



Share this post





A research paper dropped recently claiming that AGENTS.md files don't help coding agents. Naturally, a wave of YouTube videos followed: "AGENTS.md is DEAD!", "Context files are USELESS!", "Stop wasting time on CLAUDE.md!"
I read the paper. Twice.
Here's my take: the paper is methodologically weak, the conclusions are overblown, and the clickbait brigade ran with it without thinking. But -- and this is the part most people missed -- the paper accidentally points to something genuinely useful. Something I've been finding in my own experiments.
What goes into your context file matters more than most people think. Every word gets injected into every message -- and the wrong words actively work against you. The fix isn't to write more or less. It's to be deliberate about what goes where.
This is Part 2 of my Agents.md series. In Part 1, I shared 10 tips from a month of testing -- the big one being that context is precious and every word costs attention. Today I'm going deeper on that idea: what happens when a single file can't carry the weight anymore, and why the answer isn't less context but smarter context.
The Paper Everyone Is Talking About
The paper is called "Evaluating AGENTS.md: Are Repository-Level Context Files Helpful for Coding Agents?" and here's the headline finding: LLM-generated context files reduced agent performance by about 2%, while human-written files improved it by about 4%.
Both numbers are statistically insignificant. The paper itself doesn't run significance tests. Let that sink in.
But the YouTube machine doesn't care about statistical rigor. It cares about thumbnails. So we got a flood of "AGENTS.md is dead" content from people who skimmed the abstract and hit record.
Let me walk through why the paper doesn't support the conclusions people are drawing from it -- and then we'll get to what it does teach us.
Why I Don't Buy the Conclusions
The benchmarks are contaminated
The paper tests on SWE-bench and a custom benchmark called AgentBench. Here's the problem: modern coding agents are explicitly optimized against SWE-bench. Companies use SWE-bench scores as their primary marketing metric. The models are fine-tuned on these exact task types. The repos -- Django, Flask, scikit-learn -- are massively represented in training data.
Testing whether a context file helps an agent that's already memorized the playbook is like testing whether a cheat sheet helps a student who already knows the answers. You're measuring benchmark performance, not real-world capability.
Pass/fail misses the point
The paper measures one thing: does the agent's patch pass the tests? That's it.
In production, passing tests is the bare minimum. Real code quality means security, architectural consistency, proper error handling, following project conventions, using the right tools. A context file that says "use uv not pip" or "follow our error handling patterns" exists to enforce quality beyond test passage. The paper's own data shows agents DO follow these instructions when context files are present. That's the context file working. But because the evaluation only checks pass/fail, that value is invisible.
It's like evaluating a style guide by checking whether code compiles.
No separation of context file quality
This one really got me. The benchmark includes developer-written context files ranging from 24 characters to over 2,000 characters. From a single line to 29 structured sections. And the paper treats them all the same.
That's like evaluating whether documentation helps developers by averaging across a blank README and a comprehensive wiki. Of course the average looks unimpressive -- you're mixing garbage with gold.
A useful paper would have said: "Context files with X characteristics help, files with Y characteristics hurt." Instead we get: "Context files on average don't help much." That's not insight. That's noise.
Bug fixing is the wrong test
Both benchmarks focus overwhelmingly on bug fixes -- isolated, well-scoped patches. But context files matter most for designing new systems, large refactors, multi-file feature development, greenfield projects. The scenarios where you need architectural guidance, where knowing conventions across the codebase is essential.
Testing whether AGENTS.md helps fix a 12-line bug is testing in the scenario where context files provide the least value. It's like evaluating whether a project manager helps a team by measuring how fast individuals solve Leetcode problems.
Single-sample, no statistical rigor
Each agent runs once per task. No repeated trials, no confidence intervals, no p-values. LLM outputs are stochastic even at temperature zero due to infrastructure non-determinism. With single samples on small benchmarks, a 2-4% difference is noise.
To claim "LLM-generated context files reduce task success rates" based on a 2% average drop across single runs without statistical testing isn't rigorous science. It's anecdote dressed up as data.
But Here's What the Paper Gets Right
I'm not dismissing the research entirely. Buried in the flawed methodology is a signal worth paying attention to.
More instructions mean more work, more cost, and more cognitive load on the model.
The paper found that context files increased reasoning tokens by 10-22% and cost by about 20%. Agents were doing more -- more testing, more exploration, more tool calls. And in some cases, that extra work didn't translate to better outcomes.
This aligns directly with what I found in Part 1: there's a tipping point where more context stops helping and starts hurting. The attention mechanism that makes LLMs powerful has real limits. Overload it and the model loses focus on what actually matters.
The paper also confirmed something obvious but worth stating: agents follow the instructions in context files. When context files mentioned specific tools, agents used those tools more. When files described testing conventions, agents tested more. The instructions work. The question is whether they're the right instructions.
So the real takeaway isn't "context files don't work." It's "bad context files don't work, and bloated context files actively hurt." Which is... not surprising. And not what the clickbait titles say.
The Bloat Problem Is Real

Here's where theory meets practice.
You start with a lean CLAUDE.md. Project structure, a few boundaries, some code examples. It works great. Then you add deployment instructions. Then database conventions. Then infrastructure notes. Then the DevOps team needs kubectl commands documented. Then someone adds the CI/CD pipeline details.
Six months later, your context file is 800 lines of everything anyone ever thought might be useful. And the model is reading all of it, every single message, whether you're fixing a button color or deploying to production.
That's the problem the paper is actually pointing at, even if the methodology can't quite prove it. A bloated context file dilutes the signal. The model spends attention budget on infrastructure documentation when you're writing React components. On database patterns when you're debugging CSS.
The answer isn't to delete your context file. It's to break it apart.
Layering: The Fix
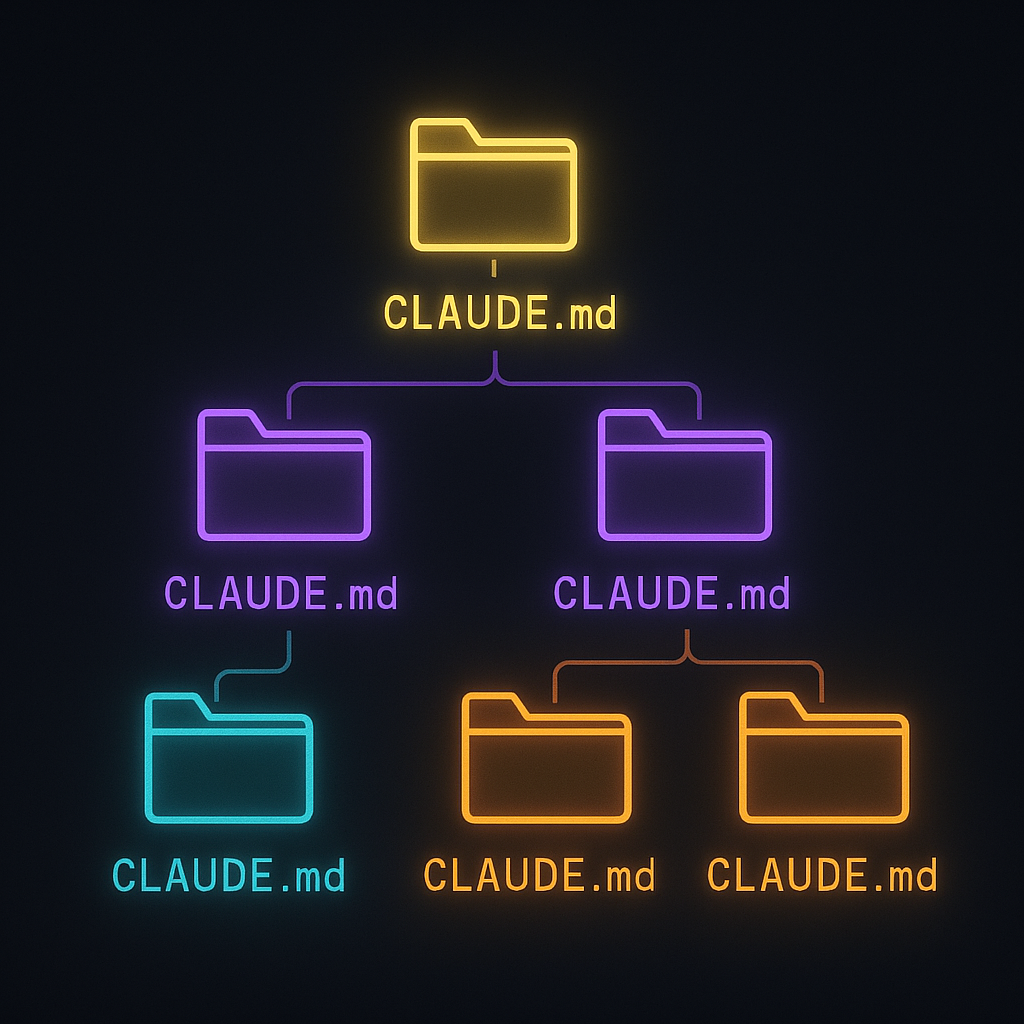
The concept is simple: instead of one massive file, create multiple context files organized by domain, role, or subfolder.
Most modern coding agents -- Claude Code, Cursor, Windsurf -- support nested configuration files. A CLAUDE.md at the project root applies globally. A CLAUDE.md inside a subfolder applies only when you're working in that subfolder. They stack: root context plus local context.
This means you can keep your root file lean and push specialized knowledge down to where it's actually needed.
Let me show you what this looks like in practice.
A Real Example: Infrastructure Context
Say you have a project with application code and infrastructure code -- Terraform configs, Helm charts, Kubernetes manifests. A common setup.
Before layering -- everything in one root file:
project/
CLAUDE.md # 600+ lines: app code standards, API patterns,
# database conventions, Terraform rules, Helm patterns,
# kubectl commands, deployment procedures, CI/CD config...
src/
infra/
terraform/
helm/
Every time you ask the agent to fix a React component, it's processing your Terraform naming conventions. Every time you're debugging an API endpoint, it's reading your kubectl cheat sheet. That's wasted attention.
After layering:
project/
CLAUDE.md # Lean: project overview, shared boundaries,
# coding standards, "see INFRA.md for infrastructure"
INFRA.md # Infrastructure architecture overview:
# what lives where, how services connect,
# high-level deployment topology
src/
CLAUDE.md # App-specific: API patterns, database conventions,
# testing standards
infra/
CLAUDE.md # DevOps operations: kubectl commands, log viewing,
# cluster management, deployment procedures
terraform/
CLAUDE.md # Terraform-specific: naming conventions,
# module patterns, state management rules
helm/
CLAUDE.md # Helm-specific: chart structure, value overrides,
# release naming patterns
Now when you're working in src/, the model sees the root context plus the app-specific context. When you're in infra/terraform/, it sees the root context plus the infra context plus the Terraform-specific context. Each combination is lean and relevant.
The INFRA.md Pattern
One pattern I've found especially useful is creating a top-level overview file that isn't a context file itself -- just a reference document.
# INFRA.md - Infrastructure Architecture
## Overview
This project runs on [cloud provider] with the following topology:
- Production: 3-node K8s cluster in us-east-1
- Staging: Single-node cluster in us-east-1
- CI/CD: GitHub Actions -> ArgoCD
## Service Map
- API Gateway: nginx-ingress -> api-service (port 8080)
- Worker: Celery workers consuming from Redis queue
- Database: PostgreSQL 15 on managed service
## Key Paths
- Terraform configs: /infra/terraform/
- Helm charts: /infra/helm/
- K8s manifests: /infra/k8s/
## Operations
For kubectl commands, log viewing, and cluster management,
see /infra/CLAUDE.md
Then in your root CLAUDE.md, a single line:
For infrastructure architecture and operations, reference INFRA.md
and the context files in /infra/.
The agent knows where to look when infrastructure questions come up, but the root context file stays clean. The specialized knowledge lives where it's used.
Why This Works
Three reasons:
1. Relevance. The model only processes context that's relevant to the current task. Working on app code? You get app context. Working on infrastructure? You get infra context. No wasted attention.
2. Maintainability. The DevOps engineer updates the infra context files. The frontend team maintains the src context. Nobody has to navigate a 600-line monolith to find the section they own.
3. Humans benefit too. This is the part people overlook. A well-structured INFRA.md isn't just for the AI -- it's documentation your team actually uses. New engineer onboarding? Point them at the layered context files. They're already organized by domain, already concise, already up to date (because the team maintains them for the AI).
You're writing documentation that serves two audiences with one effort.
The Honest Truth: Nobody Knows What Works
I want to be straight with you about something.
We're still in the 1960s of AI. There's no definitive answer to "what's the best context file structure." There's no peer-reviewed study that nails it. The paper I just critiqued is one of the first serious attempts, and it's deeply flawed. My own experiments are better but still limited.
What we have is accumulating practical experience. Thousands of engineers trying things, sharing what works, iterating publicly. That's the state of the art right now: informed experimentation.
Layering works for me. It works for the teams I've talked to. The logic is sound -- lean context files mean better attention allocation, and domain-specific nesting means higher relevance. But your project is different from mine. Your team uses different tools. Your codebase has different patterns.
So take the principle -- context is precious, keep it lean, layer by domain -- and experiment. See what works for your setup. Measure the output quality. Iterate. That's the only honest advice anyone can give right now.
And be deeply skeptical of anyone who tells you they have The Answer. Especially if their answer fits neatly into a YouTube thumbnail.
Key Takeaways
What's Next
This is Part 2 of my Agents.md series. Part 1 covered the 10 foundational tips. This post went deep on the research landscape and practical layering.
We're all building the playbook together. If you try layering and find something that works -- or doesn't -- I want to hear about it.
Watch the full video: Agents.md Part 2 - Layering & Context File Optimization
Stop wasting time on AI. I run practical experiments — real lessons you can use tomorrow, biweekly.

